

看護研究における分析方法の選び方|初心者でもわかる5つのステップ
看護研究で「分析方法が決まらない…」と悩む人は多いです。
たとえば、「とりあえずアンケートを配ってから、あとで決めよう」という声も。
しかし、この方法は研究の精度や信頼性を大きく下げてしまう危険があります。
なぜなら、分析方法は
- どんな質問項目を設定するか
- データをどう集めるか
- どんな単位で入力・集計するか
…といった研究の設計全体に影響する“根幹”だからです。
この連載では、こんな悩みに寄り添います
- 分析方法をどう選べばいいかわからない
- ExcelやJASPの操作に自信がない
- 結果をどう書けば「意味が伝わる」のかわからない
本記事(第1回)では、まず 「分析の全体像」を知り、そのうえで「分析方法の選び方」 を軸に、どの研究でも共通する5つの視点をお届けします。
なぜ分析方法は最初に決めるべきなのか?
看護研究の「分析」と聞くと、つい“統計ソフトで計算すること”を思い浮かべがちです。でも実際には、分析は研究の最初から最後まで深く関わる“思考のプロセス”です。
まず、本連載では、次の4つのステージに分けて、分析にまつわる悩みを1つひとつ丁寧に解説していきます。
🔹ステージ①|計画書を書く段階
目的に合った分析方法を選ぶ
- t検定?χ²検定?そもそもどうやって決める?
- 分析手法は「質問のしかた」や「データのとり方」に直結します。
🔹ステージ②|データを集めたあと
正しくデータを入力・整理する
- 複数回答はどう入力する?IDのつけ方は?
- データ入力の時点で、分析の“質”は決まってきます。
🔹ステージ③|いよいよ分析する段階
表・グラフの作成、統計手法の実行
- Excelでどう表を作る?JASPでは何ができる?
- 「記述統計だけでいいや…」ではもったいない!
🔹ステージ④|結果を考察する段階
結果を意味づけて、伝わる文章にする
- 有意差が出なかったら?交絡因子の影響は?
- 数字の“裏にある意味”を考えることが、研究の価値を高めます。
あなたの研究が、ただの「統計処理」に終わらず、現場に意味のある“知”となるように。この連載が、その手助けになればうれしいです。
分析方法を選ぶ5つのステップ
― “なんとなく”ではなく“ロジック”で選ぶ ―
統計手法にはt検定、χ²検定、分散分析、相関分析などたくさんの種類がありますが、大切なのは「順番に沿って考えれば、誰でも選べる」ということです。
以下のように5ステップで考えていくと、自分の研究に合った手法が明確になります。
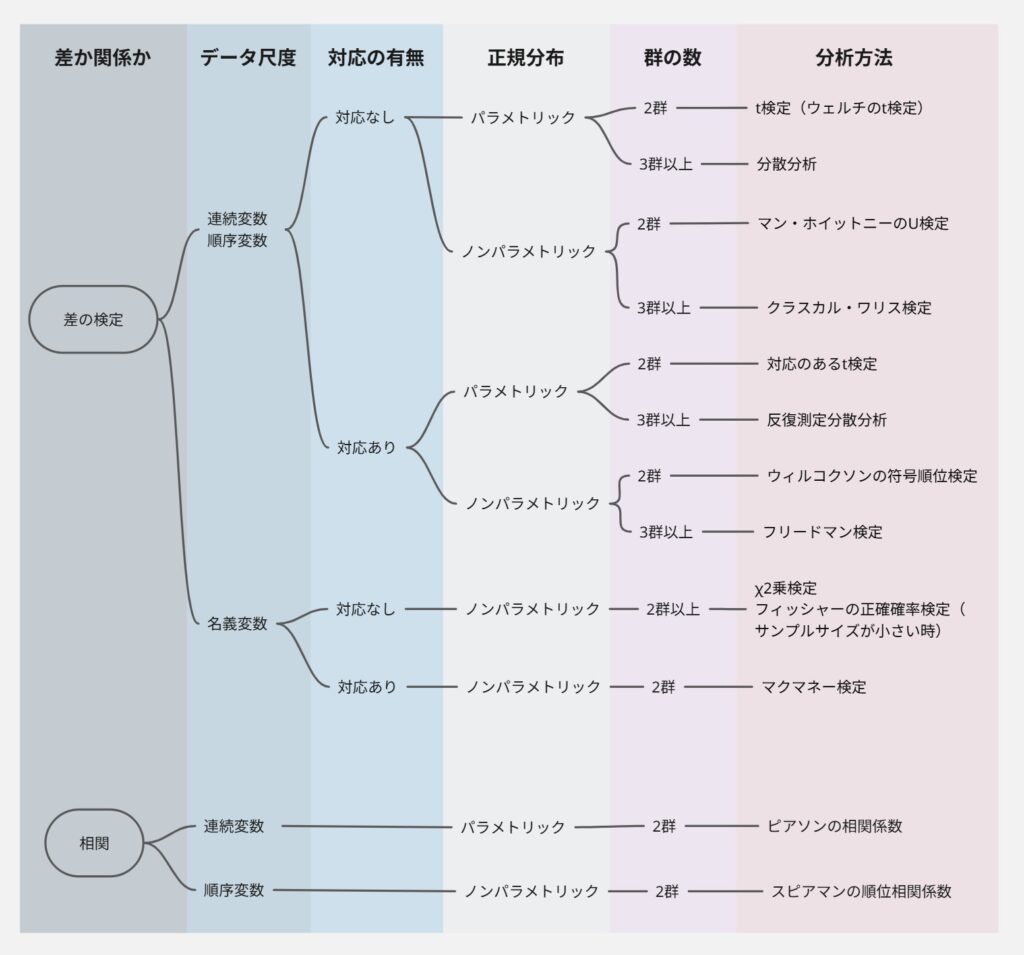
【STEP①】差を見る?関係を見る?
まず最初に考えるべきは、研究で何を知りたいのかです。
| 目的 | 例 | 検定の種類 |
|---|---|---|
| 差を見たい | 研修前後で技術度に違いはある? 離職意思あり群・なし群でストレス度に違いはある? | t検定・χ²検定など |
| 関係を見たい | 年齢が上がるとストレスも高まる? | 相関 |
研究計画で配慮すること
この段階での判断は、質問項目の形式や、回答の収集方法に大きく影響します。
- 「差」を見たい場合は、グループ間の比較が前提となるため、どのグループに属しているかを回答から取得できるよう設計します(例:「病棟A」「病棟B」など)。
- 「関係」を見たい場合は、連続変数や順序変数としてデータを取る必要があります(例:「年齢」「満足度(5段階)」など)。
つまり、目的に応じて、質問形式そのものを設計段階から調整する必要があるということです。
【STEP②】データの尺度は?
次に、データの尺度(変数)によって、使える分析方法は変わります。
| 尺度 | 例 | 検定の種類 |
|---|---|---|
| 間隔・比率尺度(=連続変数) | 点数・体重 | t検定、分散分析など |
| 順序尺度(=順序変数) | 4段階満足度 | マン・ホイットニーのU検定、ウィルコクソンなど |
| 名義尺度(=名義変数) | 性別・病棟名 | χ²検定、フィッシャーの正確確率検定 |
研究計画で配慮すること
このステップは、研究計画の段階で質問項目の設計に深く関わります。
- 名義尺度(例:性別・病棟名)を測定したいなら、選択肢を明確に分類できる形式で質問項目を作る必要があります。
- 順序尺度(例:満足度の4段階)を使いたいなら、「順番」に意味があることが読み手に伝わるような選択肢設計が重要です。
- 間隔・比率尺度(例:体重、年齢)を扱う場合は、自由記述式で数値を入力できるようにし、単位や範囲も指定しておくとデータの質が上がります。
つまり、使いたい分析手法に応じて、どんな形式で回答を集めるべきかを設計段階で決めることが不可欠です。
【STEP③】対応あり?対応なし?
「対応あり」は、同じ対象者を2回測定した比較(例:研修前後)。
「対応なし」は、異なる2群を比較(例:A病棟とB病棟)。
| 対象の関係 | 例 | 検定の種類 |
|---|---|---|
| 対応あり | 研修前後で比較 | 対応のあるt検定 |
| 対応なし | 離職意思のあり・なしで比較 | 対応のないt検定、χ²検定など |
研究計画で配慮すること
このステップは、調査のタイミングや実施方法に直結します。
- 「対応あり」の場合、同じ対象者から複数回データを取得する設計(例:研修前後)が必要です。
- 「対応なし」の場合は、異なるグループからデータを独立して収集する設計になります。
つまり、どのような構造でデータを集めるのか(同一人物か、異なる群か)を計画段階で明確にしておく必要があるのです。
【STEP④】データは正規分布しているか?
パラメトリック検定(t検定など)は、データが“正規分布”であることを前提としています。
非正規分布のときは、パラメトリック検定(ウィルコクソン、マンホイットニーなど)を使います。
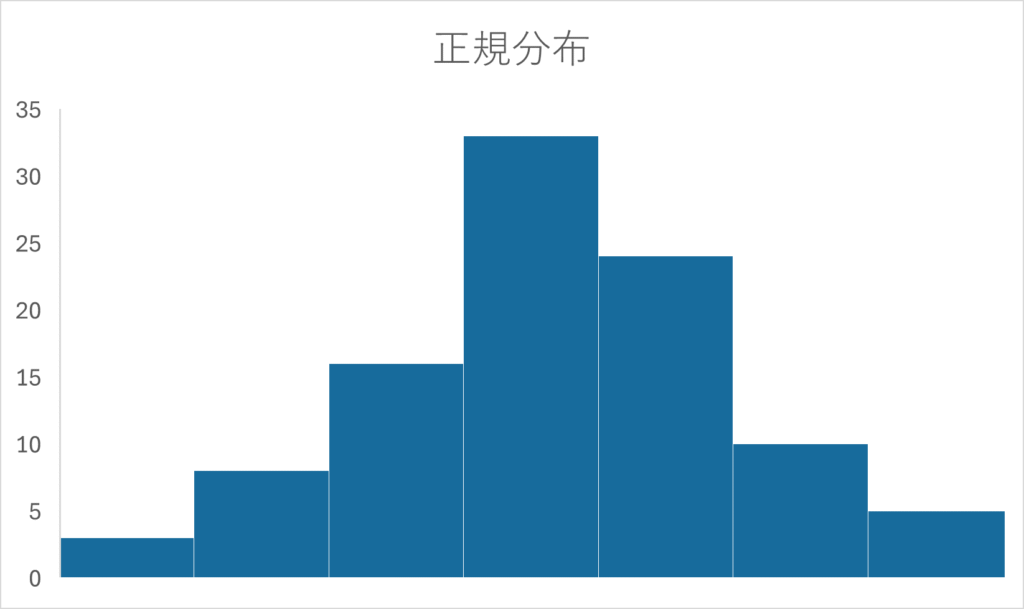
正規分布とは、ヒストグラムを描いたときに中央が盛り上がって、両側が低い山のような形をしている状態です(左下の図)。
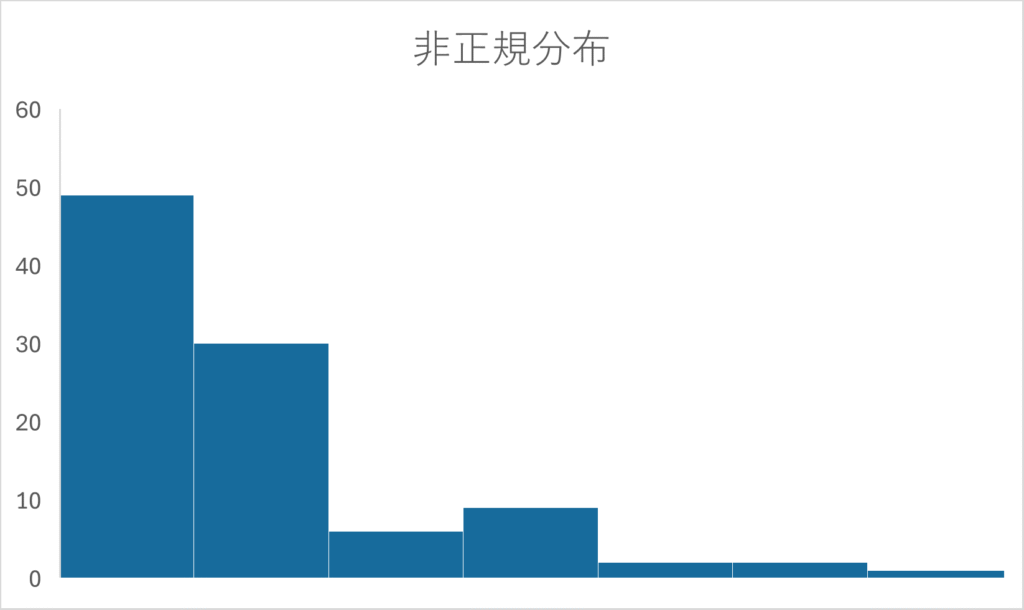
非正規分布は左右どちらかに山が偏っていたり、山が二つになっている状態です(右下の図)。
正規性の確認方法
正規分布かどうかを確認する方法には以下の2つがあります:
- ヒストグラムで視覚的に確認する:山が左右対称で中央に集まっていればおおよそ正規分布
- Shapiro-Wilk検定などの統計的検定を使う:p > 0.05で「正規性を棄却できない」(正規分布に近い)
どの変数で正規性を確認するの?
よくある質問に、「すべての変数でShapiro-Wilk検定などを行い、それぞれの変数に応じてパラメトリックとノンパラメトリックを使い分けるべきですか?」というものがあります。
現実的には、主たる変数(研究の中で一番重要な変数)で正規性を確認し、それに応じて分析手法を選ぶのがよく用いられるアプローチです。
他の変数については、目的や使用方法(副次的な変数なのか、背景情報として示すだけか)に応じて柔軟に判断します。
研究計画で配慮すること
このステップは、実際にデータを取ってから確認する必要がありますが、計画書段階でも事前の方針を明確にしておくことが重要です。
- パラメトリック検定を前提とする場合には、「正規性を確認したうえで、適切な分析方法を選択する」旨を計画書に記載しておきます。
- サンプルサイズが少ない(特に15件以下が見込まれる)場合には、正規性の判断が難しくなるため、「ノンパラメトリック検定を選択する可能性がある」ことを明記しておくと良いでしょう。
つまり、データの分布に応じた柔軟な分析選択の方針をあらかじめ明記することで、研究の信頼性と実行可能性が高まるということです。
【STEP⑤】解析対象の“群の数”は?
次に、比較するグループの数を確認します。
| 群の数 | 例 | 検定・解析の種類 |
|---|---|---|
| 1群 | A病棟の満足度のみ | 平均、中央値など |
| 2群 | 研修前後で比較、離職意思のあり・なしで比較 | t検定、χ²検定など |
| 3群以上 | A/B/C病棟で比較 | 分散分析など |
研究計画で配慮すること
このステップの選択は、サンプルの割り振り方や収集数に影響します。
- 比較したいグループが2群であれば、それぞれの群で十分なサンプルが集まるような設計が必要です。
- 3群以上であれば、群間のバランスや対象者の特性を揃える工夫が求められます。
つまり、「何群で比較するか」によって、調査対象者の選定や母集団の構成が変わってくるのです。
単変量解析だけでいいの?──多変量解析の視点も少しだけ
ここまでご紹介してきたのは、単変量解析(univariate analysis)と呼ばれるものです。
これは、「1つの結果」と「1つの要因(変数)」の関係を見るための解析方法です。
たとえば
「離職意思あり群となし群でストレス度に差があるか?」
といった 「1対1の比較」が中心でした。
でも実際の臨床では、1つの要因だけでは語れないことが多いですよね?
たとえば、ある介入の効果を検証したくても、
- 年齢
- 経験年数
- 夜勤回数
- 対象病棟の雰囲気 など
複数の要因が結果に影響しているかもしれません。
こうした複数の要因を同時に考慮して、結果との関係を見るのが、多変量解析(multivariate analysis)です。
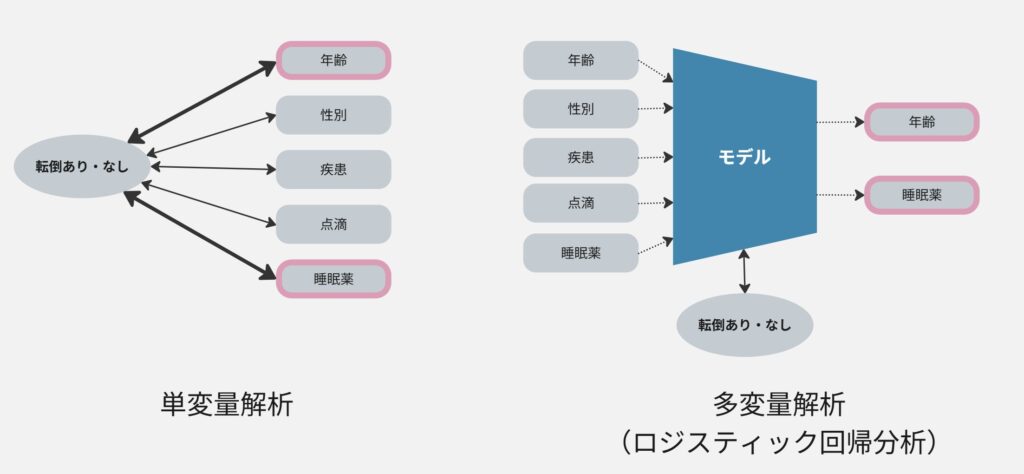
単変量解析とは?
単変量解析では、「1つの要因と、1つの結果」をセットにして関係を見ます。
たとえば、「転倒があったか・なかったか」という結果に対して、
- 年齢
- 性別
- 疾患の有無
- 点滴の有無
- 睡眠薬の使用
など1つずつ検討していきます。
多変量解析とは?
多変量解析は、「複数の要因が同時に影響しているか」をまとめて検討する方法です。
たとえば、睡眠薬の使用が転倒と関係していそうに見えても、
実は「年齢が高い人ほど睡眠薬を使っていて、転倒もしやすい」だけかもしれません。
このように、他の要因(交絡因子)を同時に考慮しながら、本当の関係性を探るのが多変量解析です。
| 変数の種類 | 例 | 検定の種類 |
| アウトカムが連続変数または順序変数 | 一日の歩数に関連する要因を探索する | 重回帰分析 |
| アウトカムが2値の名義変数 | 転倒あり・なしに関連する要因を探索する | ロジスティック回帰分析 |
| アウトカムが2値の名義変数で、時間的要素がある | がん患者の生存年数に関わる要因を探索する | コックス比例ハザード分析 |
多変量解析は「交絡因子への対策」にも使える
多変量解析は、他の変数の影響を統計的に調整した上で目的の変数の影響を見ることができる、という大きな強みがあります。
つまり、交絡因子が疑われる場合でも、解析でその影響を補正できる可能性があるのです。
まとめ|分析方法は“後回し”にしないで!
「分析は最後にやるもの」と思われがちですが、実際には研究の設計そのものに直結する重要なステップです。
質問項目、データ収集方法、変数の形式…すべてが分析方法に影響を受けます。
本記事で紹介した「5つのステップ」に沿って考えることで、分析に迷わず、伝わる研究につながります。
次回予告|あなたのデータ、正しく入力できていますか?
次回は、データ収集が終わったあとに待っている「入力と整理」のステージを取り上げます。
- Excelの入力ルールって?
- IDの振り方や複数回答の扱いはどうする?
- 入力ミスを防ぐためのチェックポイントとは?
データの質は、入力時点で決まります。
分析しやすく、考察しやすいデータを作るための実践的なコツをお伝えします。
参考文献
- 小林 美亜 編(2023).『看護研究』医学書院.
- 大林 準(2022).統計検定手法の選び方 ― 基本編 ―https://www.jstage.jst.go.jp/article/tenrikiyo/25/1/25_25-010/_pdf/-char/ja
看護学博士。臨床経験5年、研究歴10年以上。
現在は看護師さんの看護研究を支援する「Medi.Ns.Lab.」を運営し、初心者の方にもわかりやすいサポートを心がけています。





コメント
コメント一覧 (2件)
[…] 《看護研究×分析方法》シリーズ 第1回:分析方法は「最後」に決めないで… 看護研究における分析方法の選び方|初心者でもわかる5つのステップ […]
[…] 《看護研究×分析方法》シリーズ 第1回:分析方法は「最後」に決めないで… 看護研究における分析方法の選び方|初心者でもわかる5つのステップ […]